
State-of-the-art (SOTA) LLM tokens are not getting cheaper.
As the compute bottleneck tightens, inference costs are trending inexorably upwards. Providers that once offered generous free tiers are gradually introducing limits or paid plans, and the days of “free forever” appear to be numbered.
I found myself staring at the same familiar pattern: a dozen different API keys, scattered rate limits, and mounting bills. Rather than accept the inevitable, I decided to solve it. The result is TokenScavenger; a lightweight, self-hosted OpenAI-compatible router that intelligently scavenges every permanent free token across the internet and falls back gracefully only when necessary.
The Rising Cost of Intelligence
We are living through an extraordinary moment. LLMs have never been more capable, yet the raw compute required to run them continues to grow faster than hardware efficiencies can keep pace. Major providers are under pressure to monetise, and the era of seemingly unlimited free inference is quietly coming to an end.
At the same time, a quiet revolution has been happening in the background: more than a dozen providers now offer genuinely permanent free tiers; Groq, Google Gemini, OpenRouter, Cloudflare Workers AI, Cerebras, NVIDIA NIM, Mistral, and others. Each has its own strengths, quirks, and rate limits. Individually they are useful; together they represent a substantial pool of zero-cost intelligence.
The problem was coordination. No single tool existed (that I could find) that could treat all these free tiers as one unified, resilient backend.
The Birth of TokenScavenger
So I built one.
TokenScavenger is a single static Rust binary that acts as an intelligent proxy. You point your existing OpenAI SDK (or any LangChain, Vercel AI, or LlamaIndex code) at http://localhost:8000/v1 (or whichever port you decide to use) and it does the rest. It automatically discovers models from every connected provider, respects your routing policy, applies circuit breakers when a provider flakes, and surfaces everything through a clean embedded web UI.
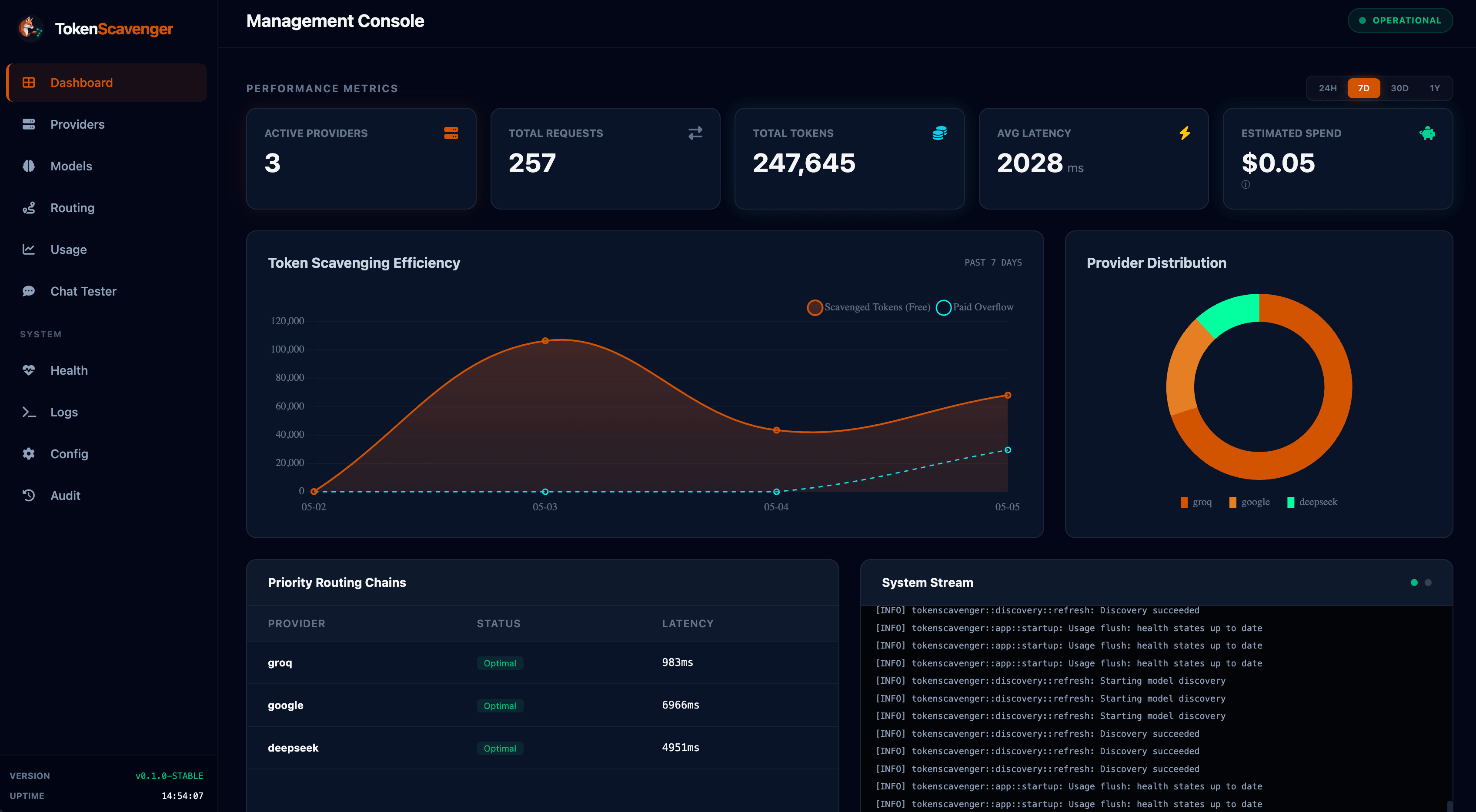
The entire application; routing engine, SQLite-backed usage accounting, Prometheus metrics, real-time logs, and admin dashboard; compiles to one executable. No Docker. No Python runtime. No external dependencies for basic operation.
How TokenScavenger Works
At its core, TokenScavenger is a policy-driven router. You define providers in a simple TOML file (or let the interactive setup wizard guide you). It then:
- Calls each provider’s
/v1/modelsendpoint on startup to build a live catalog. - Routes every request according to your free-first policy.
- Monitors health in real time with circuit breakers and exponential backoff.
- Falls back transparently when a provider returns a rate-limit error or becomes unhealthy.
- Records every token used (input and output) for accurate accounting.
The result is a single, reliable endpoint that feels like one giant free-tier LLM; until you explicitly allow paid fallback.
Key Features That Matter
- Drop-in OpenAI compatibility - change only the
base_url; everything else stays exactly the same. - 14+ built-in providers with automatic model discovery (Groq, Gemini, OpenRouter free tier, Cloudflare Workers AI, Cerebras, NVIDIA NIM, Mistral, GitHub Models, and more).
- Circuit breakers and resilience - providers that fail are temporarily sidelined without breaking your application.
- Beautiful embedded operator UI - live token usage charts, provider health, real-time logs, and instant config editing.
- Prometheus metrics - production-grade observability out of the box.
- Single static binary - runs anywhere, from a laptop to a VPS to a Raspberry Pi.
- Interactive setup wizard - first run walks you through configuration in minutes.
Getting Started Is Remarkably Simple
Head to the project website at https://kabudu.github.io/token-scavenger/ or the GitHub releases page. Download the binary for your platform (Apple Silicon, Linux, or Windows), run it once, and the setup wizard takes care of the rest. Full documentation, deployment guides, and provider matrix are available in the repository.
Try it today. The barrier to entry is deliberately low because I wanted this tool to be useful immediately, not just theoretically interesting.
Open Source by Design
TokenScavenger is fully open source under the MIT licence. The code lives at https://github.com/kabudu/token-scavenger. Provider adapters are deliberately written against a clean abstraction so new free tiers can be added with minimal effort.
If you find it useful, contributions - whether code, documentation, or simply spreading the word - are genuinely welcome. The goal was never to build yet another closed tool; it was to create something the community could own and improve.
Necessity is the mother of invention.
— Plato
In 2026, the necessity is clear: intelligence is becoming more expensive, but the free tokens are still there for those resourceful enough to gather them.
Conclusion
TokenScavenger is more than a technical curiosity. It is a practical response to a very real problem facing every engineer and small team working with LLMs today. By turning a fragmented landscape of free tiers into one coherent, observable, and resilient inference layer, it buys us time; and breathing room; before the inevitable shift to paid compute.
I built it because I needed it. I am sharing it because I suspect many of you need it too.
Give it a spin, star the repository if it helps you, and let me know what you build with it. The more of us who maximise every free token available, the longer we can keep pushing the boundaries of what is possible with AI; without breaking the bank in the process.